

DIoC Newsletter #03
DIoC Newsletter #03
Top 5 curated articles every week from Data, Intelligence and Cloud space


Welcome to the third issue of the DIoC Newsletter, here we are going to learn more about Lambda vs Kappa Architecture, Spark Structured Streaming, Principles of Modern Data Governance, Building DataOps Platform, and Common Issues in Data Platform. So let’s get started…
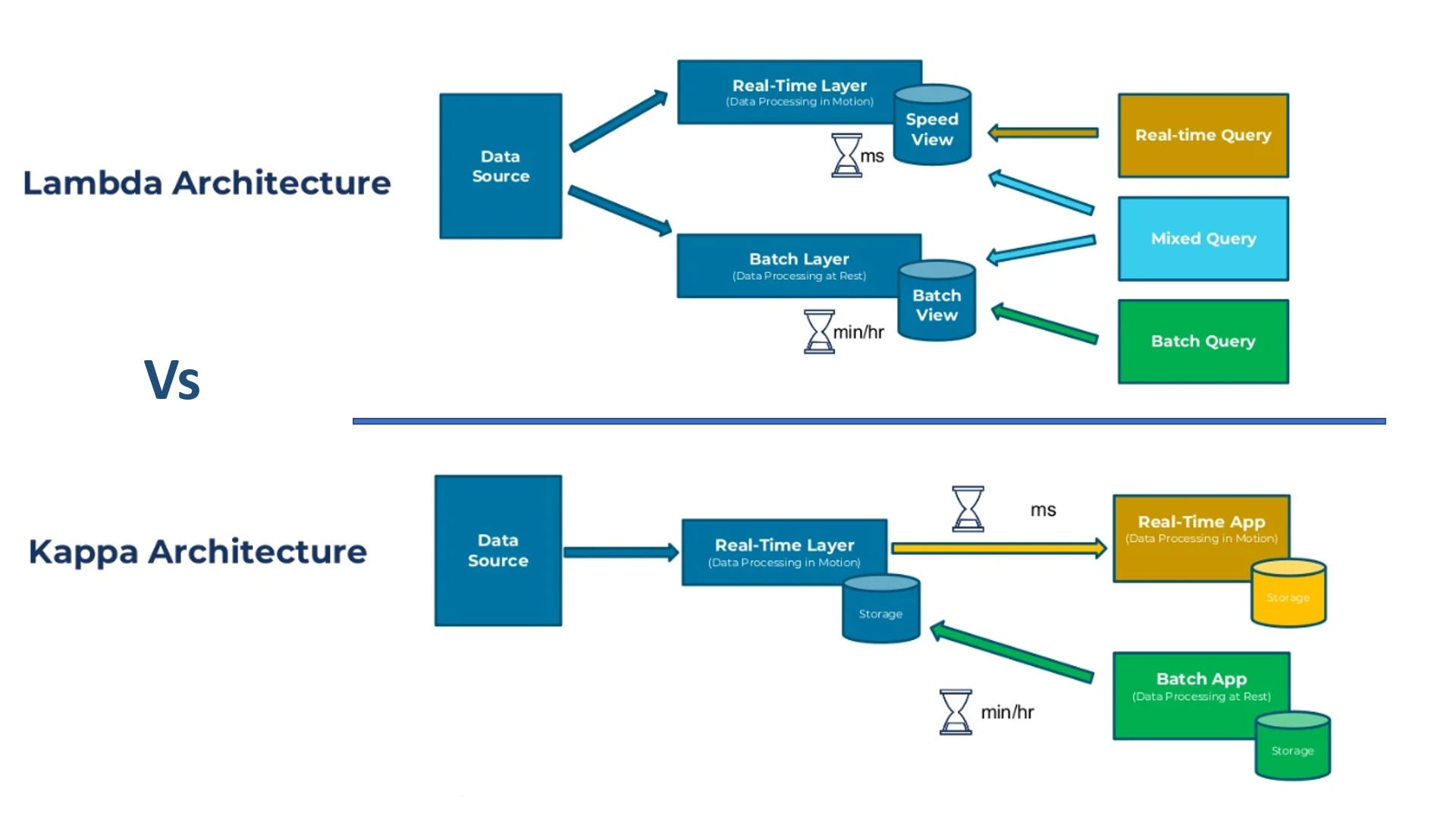
Why does Kappa Architecture for processing streaming data have the competence to supersede Lambda Architecture?
The processing of data is essential for subsequent decision-making or executable actions either by the human brain or various devices/applications etc.
There are two primary ways of processing data namely batch processing and stream processing. Typically batch processing has been adopted for very large data sets and projects where there is a necessity for deeper data analysis, on the other side stream processing for speed and quickness as soon as data gets generated at the source.
In today’s Big Data landscape, the Lambda Architecture is a new archetype for handling the vast amount of data, which can be adopted for both batches as well as stream processing of data as it is a combination of three layers namely batch layer, speed or real-time layer, and service layer.
Multiple concerns are surfacing with Lambda architecture even though it supports batch as well as speed or real-time processing together for the massive volume of data generated at lightning speed.
To replace the major bottleneck of managing two separate code bases, reducing complex infrastructures, etc. in the Lambda architecture, a single technology stack has been adopted in the Kappa architecture to perform both real-time and batch processing, especially for analytics.
We can’t completely rely on an event streaming platform to build the Kappa architecture as additional databases and analytical tools are mandatory for some use cases.
The tiered storage manages the storage without a performance impact on real-time consumers and allows for decoupling of storage from computing in platforms based on Kappa architecture.
Spark Structured Streaming

The main goal of structured streaming is to make it easier to build end-to-end streaming applications, which integrate with storage, serving systems, and batch jobs in a consistent and fault-tolerant way.
Existing distributed stream processing runs into multiple complications that don’t affect simpler computations like batch jobs:
- Consistency
- Fault tolerance
- Out-of-order data
In Structured Streaming, the above-mentioned issues are tackled by making a strong guarantee about the system: at any time, the output of the application is equivalent to executing a batch job on a prefix of the data. The last benefit of Structured Streaming is that the API is very easy to use
Beyond the basics, there are many more operations that can be done in Structured Streaming:
- Mapping, Filtering and Running Aggregations
- Windowed Aggregations on Event Time
- Joining Streams with Static Data
- Interactive Queries
Structured Streaming is continuing to complement Spark Streaming by providing a more restricted but higher-level interface.
Source: https://www.databricks.com/blog/2016/07/28/structured-streaming-in-apache-spark.html
4 Principles That Are Driving Modern Data Governance

Why are we still talking about data governance?
There are a couple of reasons that make it an inherently complicated problem:
- One, it is broad: it includes data quality, privacy, access, and lifecycle management.
- Two, it’s complicated: there are multiple personas, processes, and business use cases to cater to.
Is Data Governance as Code the solution?
Code-first principles to data governance enable us to:
- distill the high-level ideas of governance-as-code into ideas that can work in small and large companies
- discuss their practical implementation of these ideas, and
The 4 Foundational Principles of Effective Data Governance
1. Data governance IS a business priority
2. A mindset shift: Towards usage and usability, not just protection
3. Data governance should be about making decision-making scalable and easier
4. A practical shift: Towards federated computational governance
How to build a DataOps platform to break silos between data engineers and data analysts?

Data teams consisting of data analysts and data engineers are key enablers in an organization for data-driven decision-making.
But these roles act in silos, which are the biggest barrier for organizations.
In this article, the author discusses and builds a data platform that fosters effective collaboration between engineers and analysts.
Data engineers are responsible for creating and maintaining the infrastructure such as data lakes, data warehouses, and CI/CD pipelines.
Data analysts have domain knowledge and are responsible for serving analytics requests from different stakeholders to enable data-driven decision-making.
However, data analysts often rely on data engineers to implement business logic due to the required technical knowledge and complexity of applying changes to production systems.
In enterprises, the above-mentioned process-oriented roles become a bottleneck and create silos between engineers and analysts, which results in delays and overall inefficiency to serve businesses with data insights.
These silos can be broken by implementing the DataOps methodology. Teams can operationalize data analytics with automation and processes to reduce the time in data analytics cycles with the help of data engineers.
To implement the DataOps process for data analysts, you can complete the following steps:
- Implement business logic and tests in SQL.
- Submit code to a Git repository.
- Perform code review and run automated tests.
- Run the code in a production data warehouse based on a defined schedule.
The attached diagram illustrates AWS solution architecture.
Automating processes such as testing, deployment, scheduling, and orchestration in data teams has a significant impact.
It enables faster delivery of data insights with uncompromised data quality and effective cross-team collaboration.
Common Issues in Data platforms and ways to avoid them

Issue: Lack of data definition
Action: a central catalog of data definition and business glossary
Issue: Cross-system mismatch
Action: map data across the system in a unanimous fashion
Issue: Orphaned data
Action: all data files should be indexed/cataloged
Issue: Irrelevant Data
Action: identify and reconcile on a regular basis
Issue: Lack of history
Action: use snapshot enabled tools
Issue: Mishandling of late data
Action: separate data pipeline for backfilling with least downtime
Issue: Missing Attributes
Action: schema validation and reconciliation
Issue: Missing Values
Action: drop or impute
Issue: Missing Records
Action: attach metadata
Issue: Default Values
Action: cover in data catalog
Issue: Duplication of records
Action: check and purge/merge
Issue: Attribute format inconsistency
Action: standardize attribute format throughout its lifecycle
In summary, we should place controls at various levels to fix issues in our data platform:
- Fixes at the source system
- Fixes during the transformation process
- Continuous data profiling
- Guardrails at the Metadata layer
- DQ checks and alerts at the consumption layer.
Source: https://blog.devgenius.io/common-issues-in-data-platforms-3a735a4b7a42
Subscribe to my Newsletter, Follow me on LinkedIn, and never miss updates again.
What do you think about my weekly Newsletter?
If you have any suggestions or want me to feature your article, hit me up! I would love to include it in my next edition😎
Ankit Rathi is a Cloud Data Technologist, published author & well-known speaker. His interest lies primarily in building end-to-end data/AI applications/products following best practices of Data Engineering and Architecture.